Today, Cursor announced on X that they have rebuilt the way the MoE model generates tokens on Blackwell GPUs, resulting in an inference speed increase of 1.84 times.

The performance data is impressive:
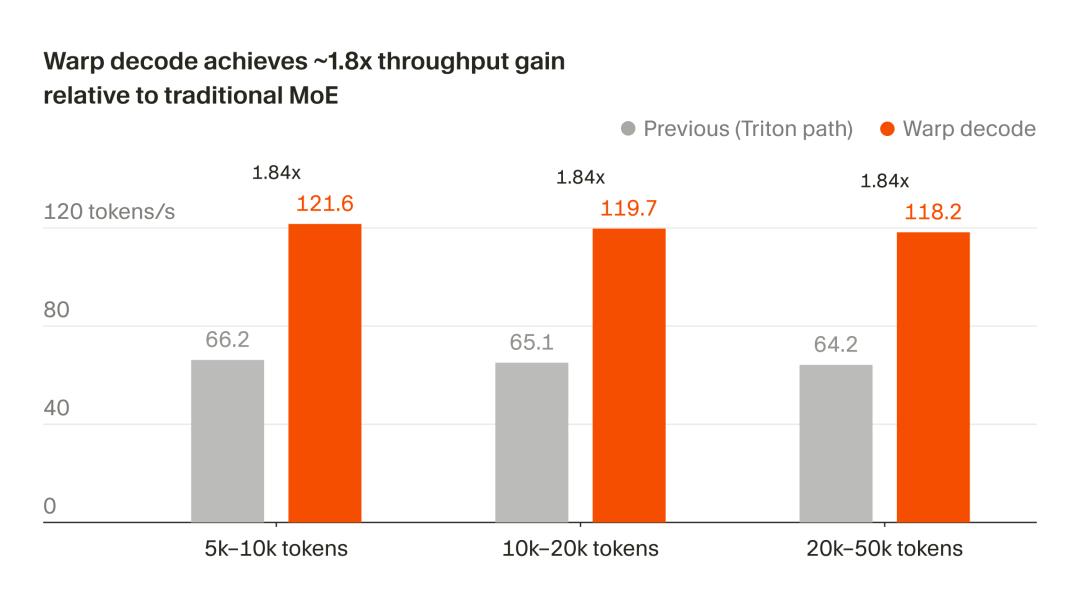
- Throughput increased from 64-66 tokens/s to 118-121 tokens/s, a 1.84x improvement;
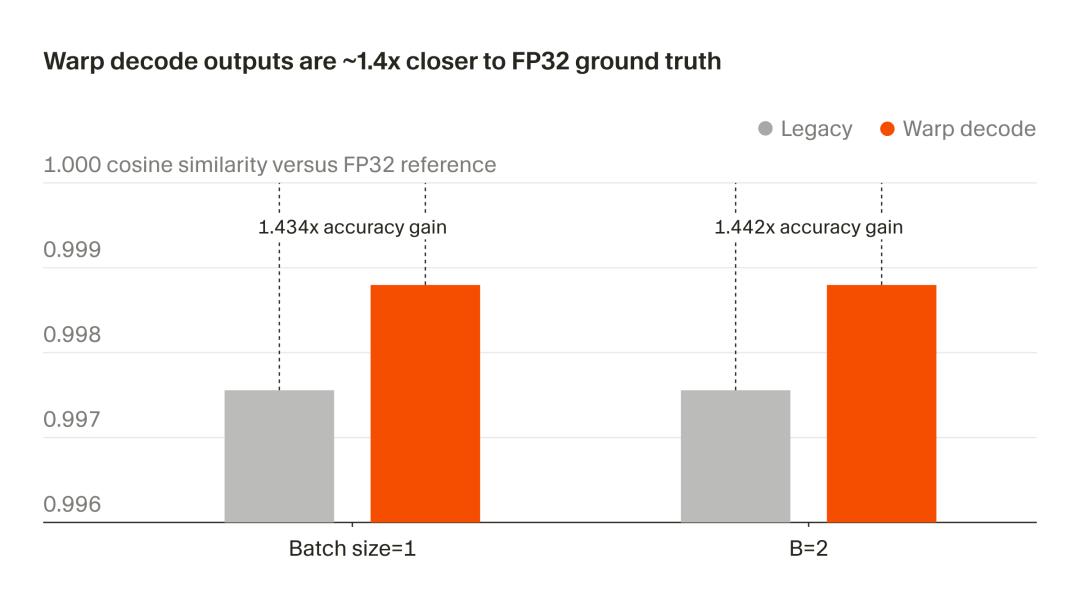
- Output quality has also significantly improved, now closer to full precision FP32, with a 1.4x increase in accuracy.
Cursor’s “output-centric” Warp Decode method directly addresses the low memory efficiency and accuracy issues of the traditional MoE model’s “expert-centric” generation method.
Today, we will break down what Cursor’s Warp Decode does and how it achieves both speed and accuracy improvements.
Traditional MoE: Expert Dispatching, Low Efficiency
Most top models today use a Mixture of Experts (MoE) architecture, which consists of dozens or even hundreds of “expert” sub-networks. During input, only a portion of these experts are activated (for example, selecting 8 out of 128 experts at a certain layer), allowing for a large parameter count while controlling actual computation.
The traditional MoE computation path generally follows these steps:
- First, a router (gate) determines which expert each token should go to;
- Then, tokens belonging to the same expert are gathered;
- After the expert completes its computation, the results are scattered back.
This traditional MoE path performs well in large batch scenarios since the shared work across experts can dilute the overhead of data management.
However, during the autoregressive decoding phase—when AI generates code—only a few tokens are generated at a time, resulting in insufficient shared work to support the process. Out of the eight stages in the traditional path, five are purely “data management” and do not perform any actual computation.
In practical applications, this means while MoE is theoretically efficient, it spends too much time transporting data, leading to low GPU bandwidth utilization and slow speeds.

Warp Decode: Focusing on Output, Bypassing Intermediaries
Since data transport is too slow, Cursor has opted for a different approach.
What exactly is warp decode? According to official descriptions:
When performing small batch decoding on Blackwell GPUs, organizing kernels around outputs rather than experts yields better results. Cursor refers to this method as “warp decode.”
Modern GPUs execute instructions in groups of 32 parallel processing channels, known as a warp. In warp decode, each warp is responsible for calculating a single output value. The warp streams the necessary weight data directly from memory, accumulating results from all eight routing experts into a continuous total, and finally writes out a result.
How does warp decode operate?
In simple terms, it shifts the focus from “experts” to “outputs,” eliminating unnecessary intermediate steps.
Warp decode enhances performance through two main mechanisms: eliminating the stages and buffers required by the traditional path, and achieving warp independence, which leads to better scheduling and improved latency hiding.
Specific implementations include:
-
Each GPU warp is responsible for a single output scalar and focuses solely on this task throughout the computation;
-
Warps are completely independent, with no synchronization or shared mutable state across them;
-
The entire MoE layer is compressed into just two fused kernels:
moe_gate_up_3d_batched: Handles gating and up-projection, with warps independently completing dot products, SiLU activations, etc., calculating intermediate values directly in registers without writing to shared memory.moe_down_3d_batched: Handles down-projection, with each warp iterating through the top-k experts, accumulating results, and finally merging partial sums into the final output using warp-level butterfly reduction (__shfl_xor_syncinstruction). This process is almost entirely completed in registers, avoiding numerous intermediate buffers and memory round trips.
-
Butterfly Reduction: Quickly merges the local partial sums of the 32 lanes within the warp into the final output scalar. After the
moe_down_3d_batchedkernel processes all top-k experts for a token, each warp accumulates contributions from different experts into its private FP32 register accumulator. At this point, the__shfl_xor_syncinstruction performs warp-level butterfly reduction, directly compiling into the underlying PTX instructionshfl.sync.bfly.
What are the major benefits of Cursor’s system?
- Completely bypasses shared memory: No need to write intermediate results to shared memory and read them back;
- No L1 cache round trips or bank conflicts: All operations are completed at the register level, resulting in very low latency;
- No explicit barriers needed: Synchronization logic is already built into the instruction’s lane mask, ensuring correctness directly.
Explosive Results: Speed and Accuracy Boosts!
According to official tests, the results are outstanding!
In Cursor’s internal inference system, tests on the Qwen-3 style model running on NVIDIA B200 showed:
- Speed: End-to-end decoding throughput increased by 1.84 times, with stable performance across different context lengths (optimized for pure generation phase).
- Accuracy: The output is now 1.4 times closer to the complete FP32 reference value.
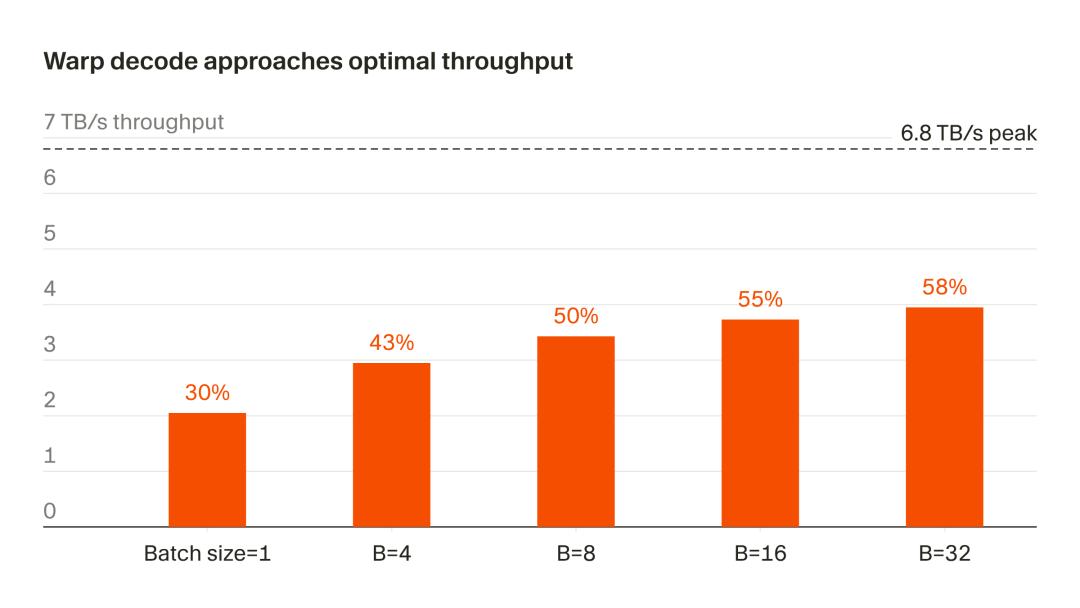
- Hardware efficiency: The B200’s measured peak for continuous memory reads is 6.8 TB/s (measured via copy kernel). With B=32, warp decode can stably reach 3.95 TB/s, equivalent to 58% of that peak.
Community Reactions: How Would It Perform on Vera Rubin?
Users on X have expressed their admiration after experiencing the model, stating, “This model is fantastic. The accuracy has improved significantly.”

Some users raised a key question: Is warp decode only operational on Blackwell, or can it be extended to other platforms? How would it perform on Vera Rubin?
According to Cursor’s official blog, warp decode is specifically designed for small batch autoregressive decoding scenarios on Blackwell GPUs (B200). For large batch prefill stages, the traditional MoE approach may still have advantages. Whether it can be extended to other GPUs in the future will depend on whether Cursor shares more details later.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.