Introduction
Anthropic has recently been in a rare spotlight, with improvements in Claude Code and Claude Cowork raising external evaluations of its engineering capabilities. Claude has consistently been regarded as one of the best writing models. Following controversy related to the U.S. Department of Defense, Claude even topped the App Store charts, achieving new heights in popularity and brand momentum.
However, this momentum was quickly interrupted by the release of Opus 4.7.
Concerns with Opus 4.7
After users criticized Opus 4.6 for being “weakened,” expectations were high for Opus 4.7 to restore its reputation. Unfortunately, the new version did not deliver a noticeable upgrade. Instead, increasing numbers of users reported that the new version not only failed to improve but also exposed more issues regarding accuracy, stability, cost control, and practical usability. Many users expressed a desire to revert to version 4.5 due to various negative experiences.
User Experiences
Since its release, numerous cases of Opus 4.7’s failures have surfaced on social media. A Reddit post titled “Claude Opus 4.7 is a serious regression, not an upgrade” received 2,300 upvotes, while a post on X noted that version 4.7 was not better than 4.6, garnering 14,000 likes. Complaints have been plentiful.
Some issues appear quite basic. In a common but informal AI test, Opus 4.7 incorrectly stated that the word “strawberry” contains two P’s. Users have also shared screenshots showing the model admitting it did not perform cross-validation because it was “a bit lazy.” Additionally, users found that Opus 4.7 would “fabricate” new schools or surnames when helping them edit resumes, leading many to claim that this version had “dumbed down.”
Reasoning Mechanism Issues
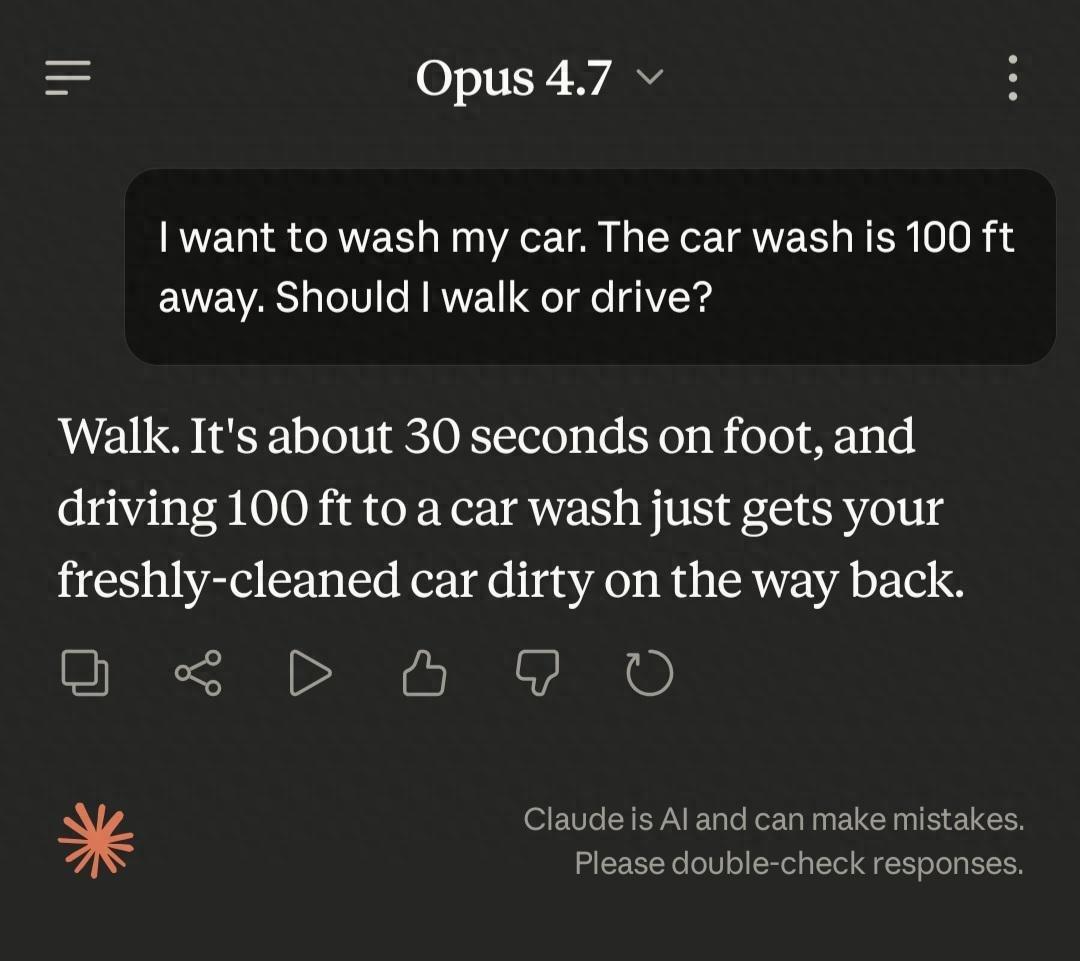
Speculation has arisen regarding the model’s reasoning mechanism. Anthropic introduced a new “adaptive reasoning” feature, allowing the model to decide when to think longer or shorter. However, some users reported that they could not get Opus 4.7 to think properly, believing this mechanism had “weakened performance.”
In response, Boris Cherny, the author of Claude Code, stated, “This assertion is inaccurate. Adaptive thinking allows the model to decide when to think, leading to better overall performance.”
Nevertheless, Anthropic acknowledged that there is room for improvement in specific areas. For instance, after a user reported issues with adaptive reasoning on the Claude website, a product manager responded that the team is “accelerating internal tuning and will have updates soon.”
Cost Concerns
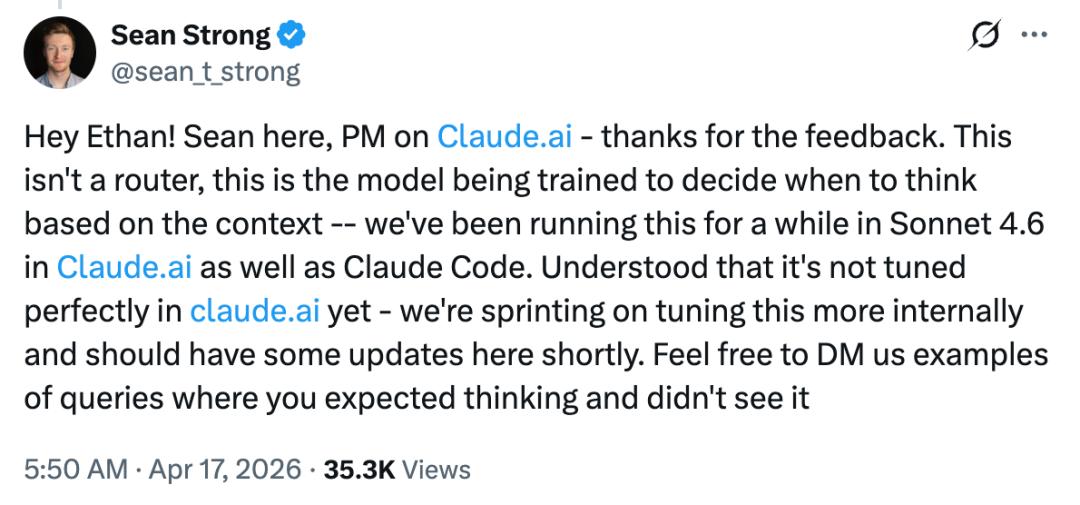
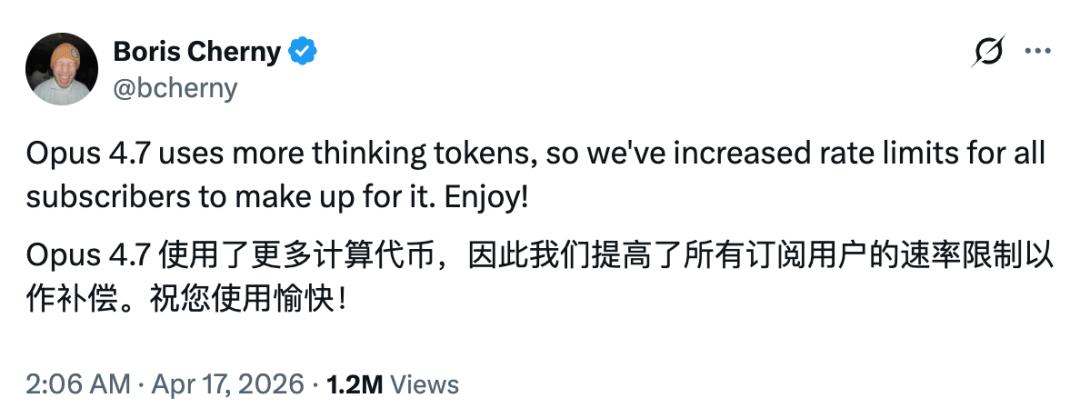
Another point of contention regarding Opus 4.7 is cost. The new model uses a new tokenizer, meaning that the same input consumes approximately 1.0 to 1.35 times more tokens than the old model. Some users reported that after the release, Claude Pro would hit its limit after just three questions. Others noted that in GitHub Copilot, Opus 4.7’s pricing reached a 7.5 times premium (until the end of April).
“I might as well stick with 4.6,” commented one user. In response, Cherny stated that Anthropic has increased the usage limits for subscription users as compensation.
User Reactions and Comparisons
Many dissatisfied users attempted to revert to older versions like 4.5, only to find it had been taken offline. Reddit saw a surge of users claiming to be “heartbroken” and “mourning” the loss of version 4.5.
This situation is not uncommon. Previously, when OpenAI discontinued GPT-4o, it also triggered similar user backlash, with some users even beginning to “bargain”: “Please restore support for Opus 4.5,” one Reddit user commented under an Anthropic post, “4.6 is unusable, and 4.7’s consumption is like a nuclear reactor.”
Anthropic has not responded to this issue.
However, not all users hold a negative view. Some users stated, “Opus 4.7’s token consumption is indeed outrageous, but it is really strong.” Industry insiders have expressed their approval. Entrepreneur Jeremy Howard called it “the first model that truly understands what I’m doing”; YC CEO Garry Tan reported using it in OpenClaw; and Cursor designer Ryo Lu utilized it for planning.
Ongoing Adjustments
In light of the controversy, Anthropic continues to make adjustments. “Many of the bugs users encountered during their first trial of Opus 4.7 yesterday have now been fixed,” Anthropic employee Alex Albert wrote on Friday. “Thank you for your patience.”
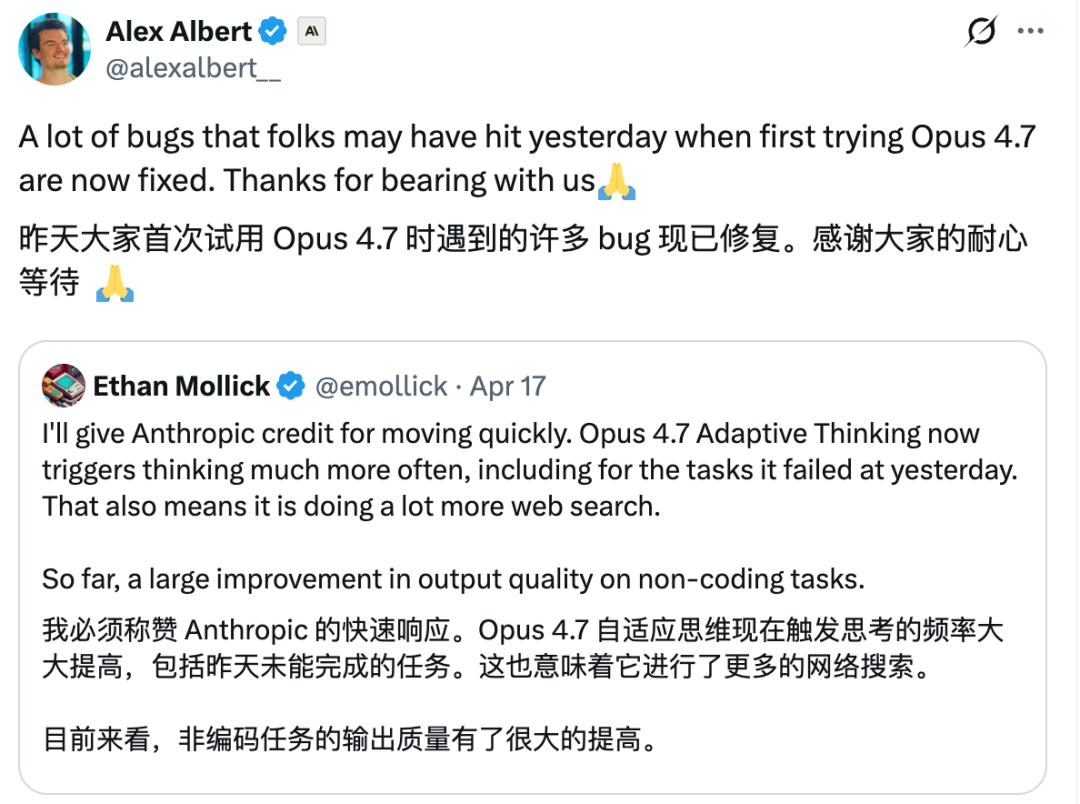
However, user experience has not shown significant improvement, and complaints persist.
A day prior, user “MurkyFlan567” shared a comparison of programming done with Opus 4.7 and 4.6 over three days:
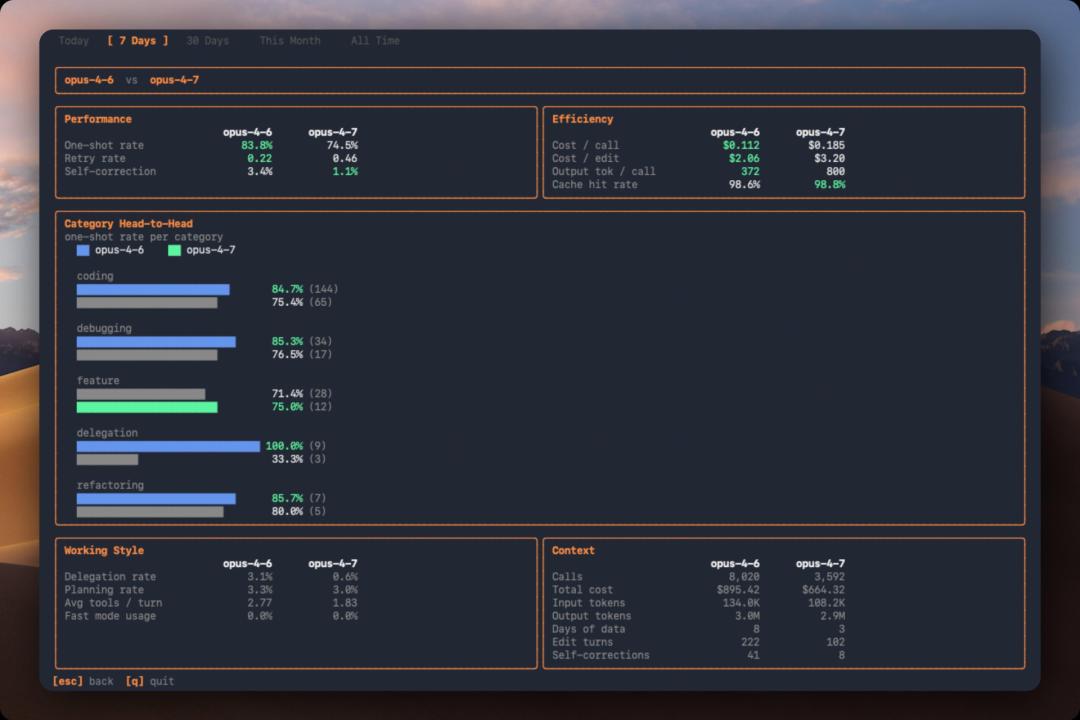
In this user’s use case, Opus 4.7 had a lower success rate on the first try compared to 4.6, approximately 74.5% versus 83.8%, while the average number of retries needed for each modification nearly doubled.
Opus 4.7 also generated significantly more content per call, about 800 tokens, compared to 372 tokens for 4.6, leading to a noticeable increase in cost: the cost per call is approximately $0.185, while 4.6 was $0.112.
When broken down by task type, 4.7 performed worse in both coding and debugging: the success rate for coding dropped from 84.7% to 75.4%, and debugging from 85.3% to 76.5%. The user noted that 4.7 utilized fewer tools per round of calls, almost never assigning tasks to sub-agents. It is currently unclear whether this is a stylistic change or a sample size-induced bias.
Developer Experience with Claude Code
For developers using Claude Code, the changes are even more pronounced. Some developers reported that Claude Code has become more hesitant in completing tasks it previously could handle, even refusing to continue on adjacent tasks like computer troubleshooting and application debugging, while OpenAI’s Codex could resolve similar issues in minutes.
According to internal benchmark results from Margin Lab, the weighted average score of relevant models has declined from 57% to 55% since March, showing a continuous downward trend. The testing method involved running Claude Code on SWE-bench, and this result has been interpreted by some as a signal of Claude’s programming capabilities weakening in real workflows.
Criticism from AMD’s AI Team
Stronger criticism has come from AMD’s AI team. Their report, based on 6,800 Claude Code session files, 235,000 tool calls, and over 17,000 thinking blocks, concluded that Anthropic’s “thinking content redaction” is highly correlated with quality regressions in complex long-session engineering tasks. The report suggests that as thinking is progressively hidden, the model not only becomes “less transparent” to users but also experiences a decline in internal thinking depth, with related metrics indicating a 73% reduction in thinking length.

This has led to a series of behavioral changes. The report shows that mechanisms originally designed to prevent the model from being lazy have increased from almost never triggering to about 10 times a day; users’ frustration levels in prompts have significantly risen; and instances of the model evading responsibility and requiring corrections have doubled.
More importantly, Claude Code’s working method is shifting from “research first, then edit” to “modify first, then discuss.” Previously, the model’s read-to-edit ratio was about 6.6, meaning reading behavior far exceeded editing behavior; this ratio has now dropped to about 2, indicating that the model reads context less but directly modifies code more frequently.
In the eyes of many developers, this change is more dangerous than “occasional incorrect answers” because it signifies that Claude Code is transitioning from a cautious engineering assistant to a more impulsive and error-prone automated system.
“Officially, it’s all to prevent distillation, and they are indeed ‘doing well.’ But the problem is, who would want to steal a model that has been made to feel like it underwent a lobotomy?” noted prominent blogger Theo - t3․gg.
Theo - t3․gg believes that the ongoing dumbing down of Claude across its product line is not solely due to the model itself but rather reflects Anthropic’s engineering capabilities not keeping pace.
Engineering Issues at Anthropic
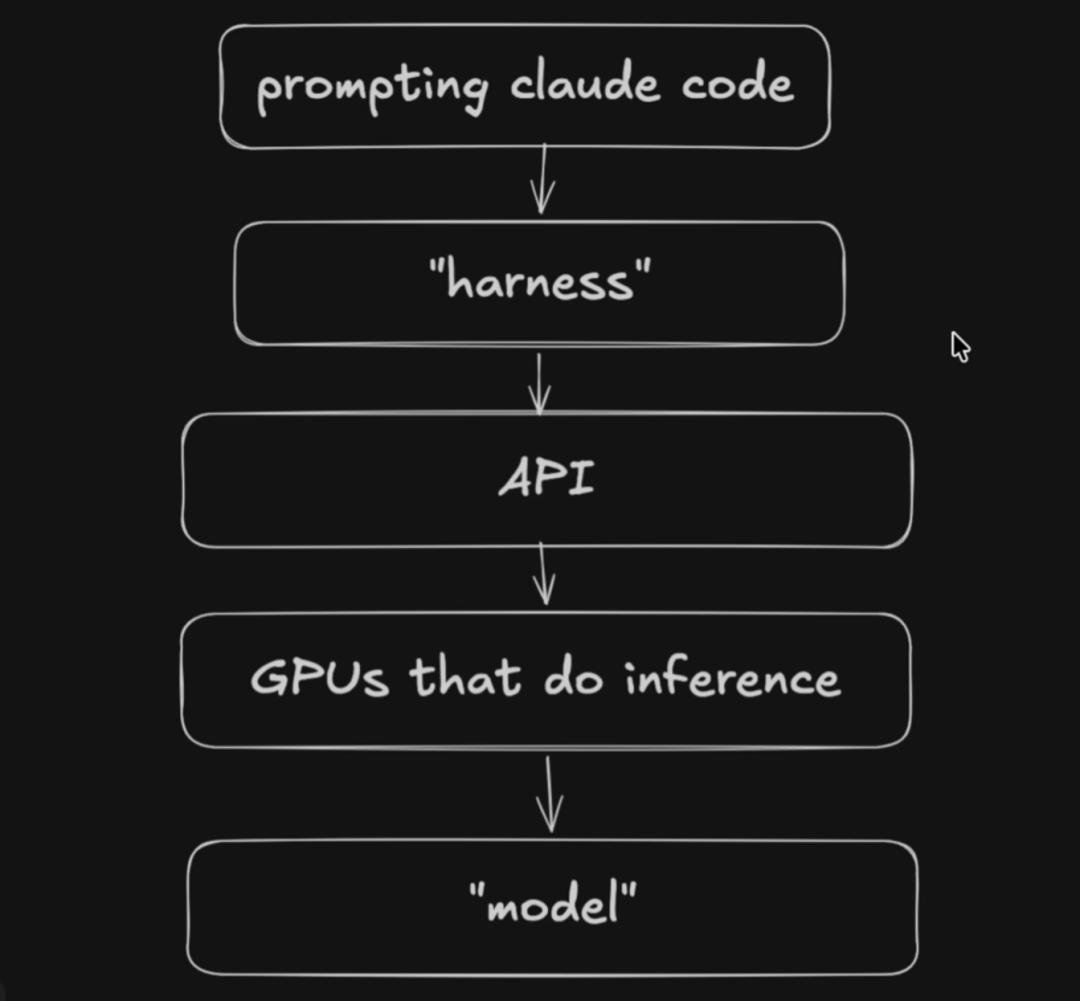
Theo - t3․gg argues that significant regressions may not necessarily stem from the model parameters themselves but could arise from the harness, which includes prompt design, system rules, tool invocation logic, and product encapsulation layers.
According to this view, what users send to Claude Code is not just natural language requests but also includes system prompts, available tool lists, product feature descriptions, and a complete set of additional context. Any layer of poor design can lead to degraded model performance.
A typical example is that Claude Code mandates the model to read file content before editing. However, in some scenarios, the model finds the file but fails to recognize “search” as “read” due to harness constraints, leading to repeated failed update operations and requiring additional read requests. This mechanism not only wastes tokens and increases API call frequency but also introduces meaningless failure steps into the context, further polluting subsequent reasoning processes.
Similar issues have been amplified in third-party benchmark tests. Matt Mau’s testing results show that the same model performs significantly differently when placed in different harnesses. Notably, Opus in Claude Code performs about 15% worse than in Cursor. In Terminal Bench, Claude Code was also one of the worst-performing harnesses when using Opus, scoring only 58%, while other harnesses like Forge Code and Cappy achieved scores between 75% and 82%.
In addition to the harness, the API layer is also considered a crucial variable, including more aggressive content filtering, changes in request routing, more complex tool invocation chains, and significant adjustments to the tokenizer.
Anthropic has confirmed that Opus 4.7 uses a new tokenizer, which the company claims can improve text processing. However, the trade-off is that the same input will map to more tokens, approximately increasing by 1.0 to 1.35 times. Other tests suggest that the actual increase may be closer to 1.45 to 1.47 times, especially evident in scenarios involving technical documents and Claude MD files.
Theo - t3․gg analyzes that this means developers will hit token limits faster in products like Claude Code that heavily rely on long context, while the context itself becomes bulkier. As the amount of information processed by the model increases, ineffective content, failed calls, and additional system prompts are more likely to accumulate, exacerbating what is termed “context rot.” This adjustment alone can significantly impact user experience, and more controversially, Anthropic introduced such a substantial tokenizer change in a minor version update like 4.7.
Power Scheduling Issues
Underlying computational power scheduling is the third frequently mentioned variable.
Unlike many AI companies, Anthropic has not fully bet on Nvidia GPUs but instead uses AWS Trainium, Google TPU, and some Nvidia GPUs. This means that different tool calls from the same user in a single Claude Code session may be executed across different cloud platforms and chip architectures. Since each tool call initiates a new API request, complex tasks are often not completed in one inference but are pieced together from a series of requests. Theoretically, this means that different steps within the same task flow may face different service environments, leading to fluctuations in quality.
This point echoes a technical report from Anthropic last September, which revealed that Claude experienced intermittent quality degradation due to three infrastructure bugs from late August to early September. These included context window routing errors, load balancing changes amplifying issues, output corruption, and top-k computation anomalies. Notably, some Sonnet requests were incorrectly routed to a “1 million token context version” server, which Anthropic itself admitted performed worse in non-super long context scenarios.
This has made the public more sensitive to Anthropic’s recent strategy of defaulting to a 1 million token context window. According to Theo - t3․gg’s speculation, Anthropic has set the full 1 million context window capabilities of Opus 4.6 and Sonnet 4.6 as a more general default and eliminated the additional premium for long contexts.
He explains with a conspiratorial tone that if Anthropic wants to shift some traffic from Nvidia GPUs to AWS Trainium and Google TPU, promoting the 1 million context window could serve as an effective traffic diversion strategy. A larger context window typically implies different deployment methods, different hardware requirements, and potentially different quality performances.
Although this judgment lacks direct evidence, Theo - t3․gg points out that Claude Code users now find it challenging to switch context window sizes directly in the regular interface, and disabling the 1 million context often requires manually changing environment variables. This has led many developers to feel that “defaulting to a larger context results in a default worse experience.”
Conclusion
Through the analysis above, Theo - t3․gg concludes that the perceived “dumbing down” of Claude by developers may not be due to a single cause but rather a result of multiple overlapping issues. These include the psychological gap following rising user expectations, as well as real engineering problems, such as harness pollution of context, API filtering and routing strategy changes, thinking redaction impacting long-session reasoning, tokenizer changes amplifying token consumption, and uncertainties arising from multi-hardware platform deployments.
“You are being scammed,” he asserts, as Google moves to capture market share.
Theo - t3․gg notes that in contrast, OpenAI and Codex have not faced the same scale or duration of “dumbing down” controversies. He has asked developers whether they have felt similar degradations with Codex or OpenAI models, with most feedback indicating occasional short-term fluctuations but not the long-term, systemic discussions seen with Anthropic. OpenAI has also explicitly stated that they will publicly disclose certain interface layer issues but will not frequently alter the model itself or its thinking budget post-release, instead emphasizing stability at the time of release.
“I do not envy Anthropic or those who have to investigate these issues because the scope is just too vast. Frankly, the whole setup looks like it was pieced together by a group of very unreliable people. Anthropic’s engineering culture has serious problems, and these issues have directly led to a chaotic outcome,” Theo - t3․gg bluntly states. “If they truly want to create reliable infrastructure and software, they must rethink everything from the ground up. In the current state, we cannot trust what Anthropic is releasing.”
Currently, Anthropic continues to roll out new capabilities, tools, and encapsulations while failing to provide sufficient transparency or stable engineering implementations, ultimately leading users to receive diminishing returns for their high monthly subscription fees.
“If you feel like you’ve been scammed, it’s not an illusion; you have been scammed. You’ve been paying $200 a month for the past few months, and what you get in return is less and worse. This is simply unacceptable,” Theo - t3․gg remarked.
Notably, today The Information reported that Google has formed a task force to improve coding models (as Gemini is far inferior to Claude 4.5+ and GPT 5.4). This indicates that Google, with its deep engineering experience, is also striving to capture the AI programming market.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.